Kubernetes组件etcd相关知识点总结
本文总结补充自马哥教育相关视频
简介
etcd是CoreOS团队于2013年6月发起的开源项目,其的目标是构建一个高可用的分布式键值(key-value)数据库。Etcd内部采用raft协议作为一致性算法等基于Go语言实现。
官方网站:https://etcd.io/
github 地址:https://github.com/etcd-io/etcd
官方硬件推荐:https://etcd.io/docs/v3.4/op-guide/hardware/
etcd具有下面这些属性:
- 完全复制:集群中的每个节点都可以使用完整的存档
- 高可用性:Etcd可用于避免硬件的单点故障或网络问题
- 一致性:每次读取都会返回跨多主机的最新写入
- 简单:包括一个定义良好、面向用户的API(gRPC)
- 安全:实现了带有可选的客户端证书身份验证的自动化TLS
- 快速:每秒10000次写入的基准速度
- 可靠:使用Raft算法实现了存储的合理分布Etcd的工作原理
配置文件
etcd可以直接将启动参数写在service文件中
|
或者可以不将启动参数写在service文件中,使用config文件方式定义,例如:
创建etcd配置文件
|
创建systemd配置文件
|
etcd 的基本使用
etcd有多个不同的API访问版本,v1版本已经废弃,etcd v2 和 v3本质上是共享同一套raft 协议代码的两个独立应用,接口不一样,存储不一样,数据互相隔离,也就是说如果从etcd v2 升级到 v3 原来v2 的数据还是只能用v2 的接口访问,v3 的接口创建的数据也只能通过v3 的接口访问
增加和修改,如果存在则替换
|
对某个key监听操作,当/key1发生改变时,会返回最新值
etcdctl watch /key1
|
监听key前缀
etcdctl watch /key --prefix
监听到改变后执行相关操作
etcdctl watch /key1 -- etcdctl member list
etcd 集群成员的心跳信息
|
etcd 集群的成员信息
|
显示etcd群集的详细信息
|
查看所有的key
|
etcd 中查询k8s相关信息
查看所有的key
|
查看kubernetes中所有pod的信息
|
查看kubernetes中所有namespace的信息
|
查看kubernetes中所有deployments的信息
|
查看calico网络组件信息
|
查看指定的key
|
查看所有calico的数据
|
etcd备份与恢复
etcd数据备份流程
ETCD 不同的版本的 etcdctl 命令不一样,但大致差不多,本文备份使用
napshot save, 每次备份一个节点就行。
命令备份(k8s-master1 机器上备份):
|
备份脚本(k8s-master1 机器上备份):
|
etcd 数据恢复流程
当etcd集群宕机数量超过集群总节点数一半以上的时候(如总数为3台,宕机2台),就会导致集群宕机,后期需要重新恢复数据,则数据恢复流程如下:
- 恢复服务器系统
- 重新部署etcd集群
- 停止kube-apiserver/controler-manager/scheduler/kubelet/kube-proxy
- 停止ETCD集群
- 各ETCD节点恢复同一备份数据
- 启动各节点并验证ETCD集群
- 启动kube-apiserver/controler-manager/scheduler/kubelet/kube-proxy
- 验证k8s master 状态及pod 数据
准备工作
- 停止所有 Master 上
kube-apiserver服务
|
- 停止集群中所有 ETCD 服务
|
- 移除所有 ETCD 存储目录下数据
|
- 拷贝 ETCD 备份快照
|
恢复备份
|
上面三台 ETCD 都恢复完成后,依次登陆三台机器启动 ETCD
|
三台 ETCD 启动完成,检查 ETCD 集群状态
|
三台 ETCD 全部健康,分别到每台 Master 启动 kube-apiserver
|
检查 Kubernetes 集群是否恢复正常
|
kubeasz备份恢复
|
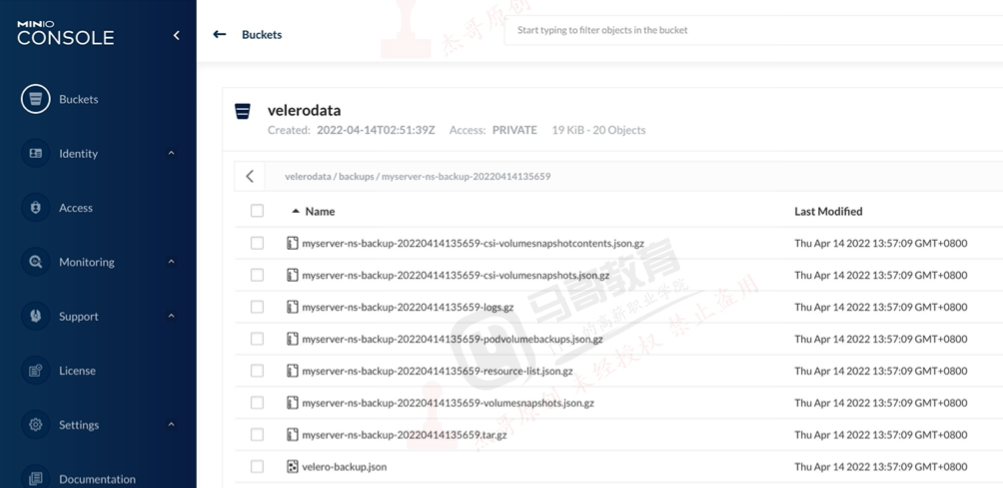
Velero 结合mino 实现k8s 业务数据备份与恢复
Velero 是一个云原生的灾难恢复和迁移工具,它本身也是开源的,采用Go语言编写,可以安全的备份、恢复和迁移 Kubernetes集群资源数据。
Velero 是西班牙语意思是帆船,非常符合Kubernetes社区的命名风格,Velero的开发公司Heptio,已被VMware收购。
Velero 支持标准的K8S集群,既可以是私有云平台也可以是公有云,除了灾备之外它还能做资源移转,支持把容器应用 从一个集群迁移到另一个集群。
minio 安装
|
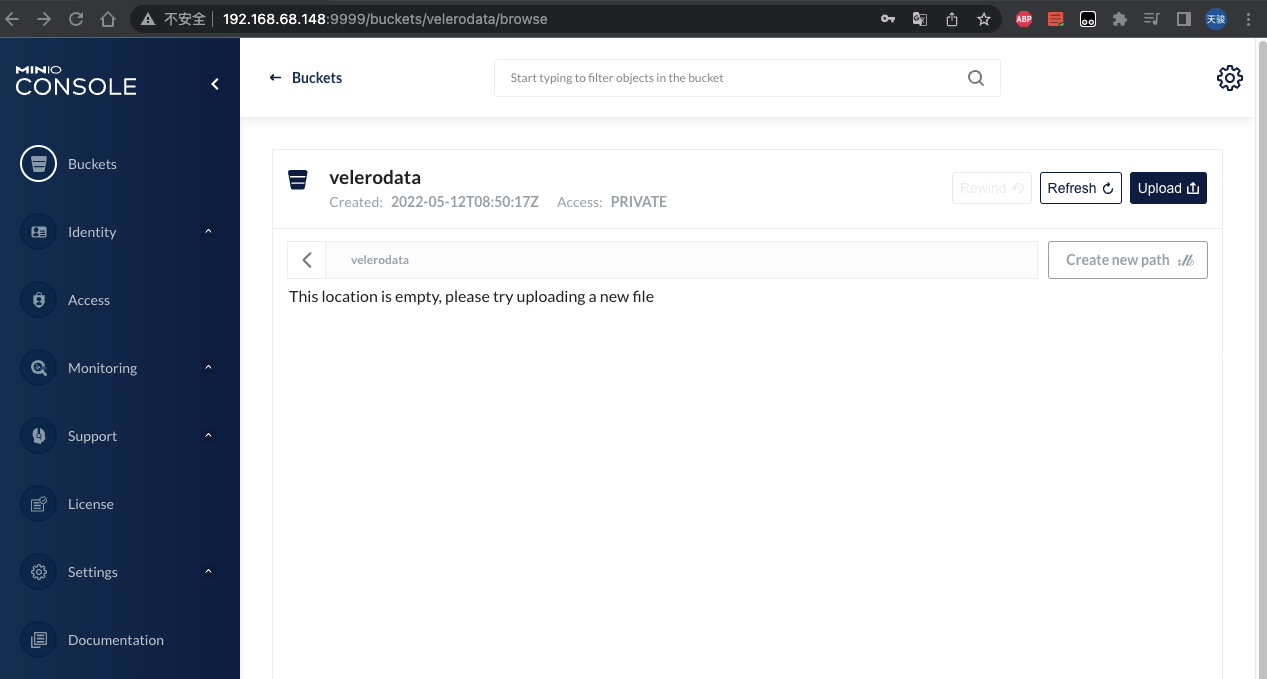
浏览器访问9999端口:

使用创建容器时指定的用户名密码登录,并创建一个名为velerodata的bucket:
velero 安装
|
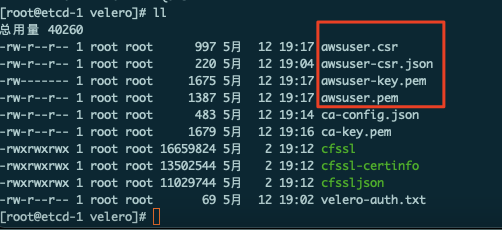
签发完成后在当前目录有如下文件:
|
再次查看
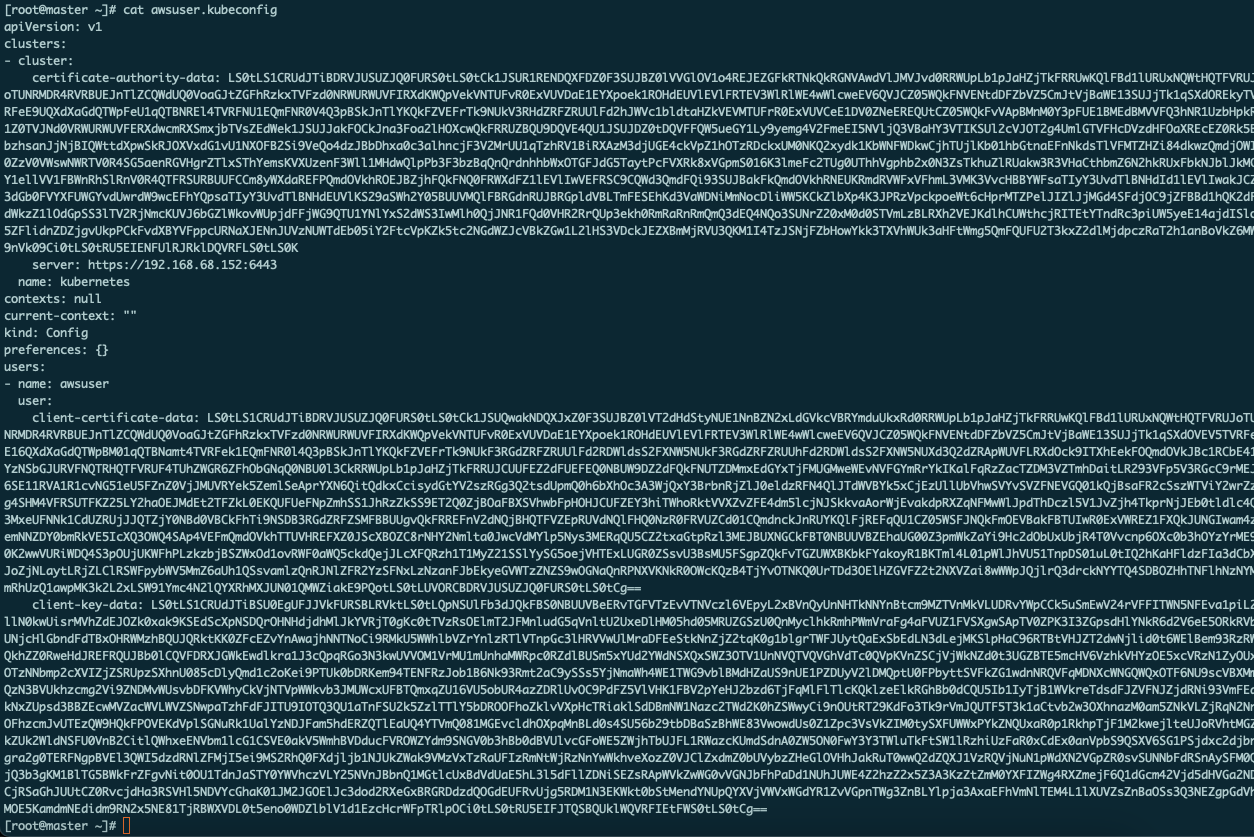
可以看到用户公钥私钥已经加入
|
可以看到上下文信息已经写入
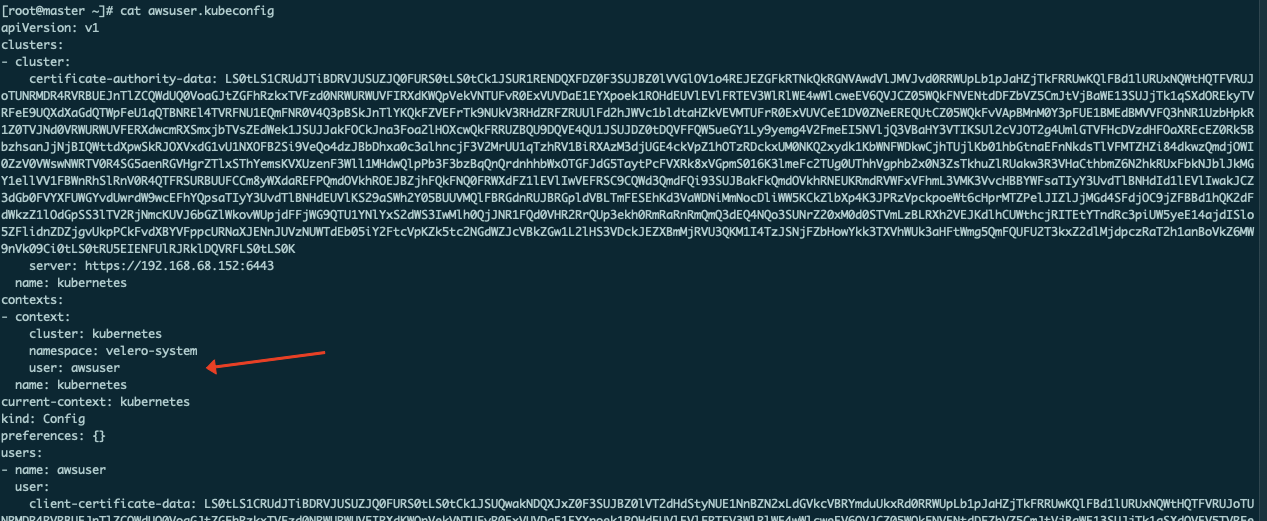
|
可以看到velero已经启动
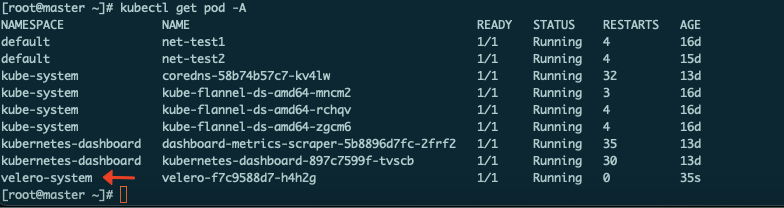
此时velero安装完成
使用velero + minio 备份
|