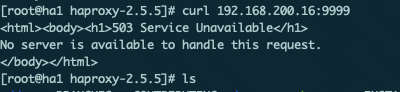
listen stats mode http bind 192.168.200.16:9999 # 与keepalive的vip地址一致 stats enable log global stats uri /haproxy-status stats auth haadmin:123456
listen web_port bind 0.0.0.0:80 mode http log global balance roundrobin server web1 192.168.68.152:8080 check inter 3000 fall 2 rise 5 server web2 192.168.68.153:8080 check inter 3000 fall 2 rise 5
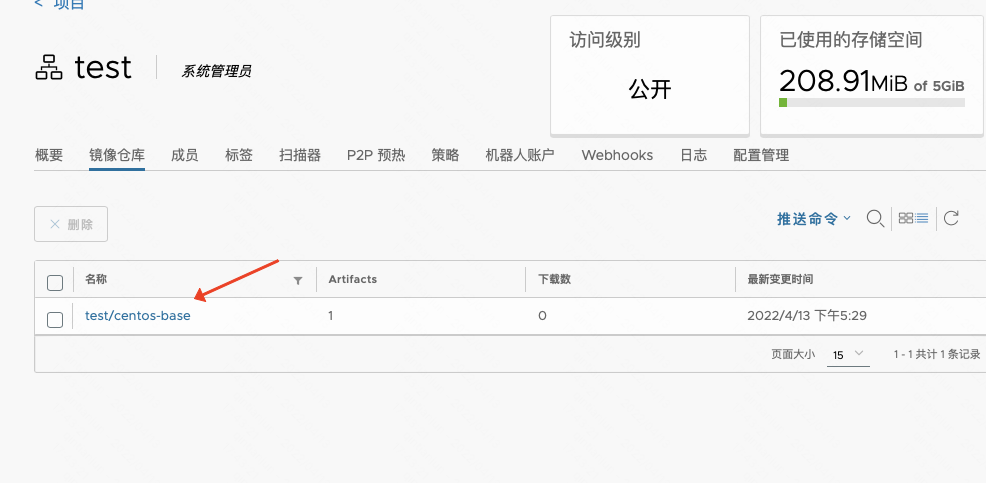
[root@ha1 harbor]# docker login harbor.magedu.net/test/centos-base Username: admin Password: WARNING! Your password will be stored unencrypted in /root/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store
[root@ha1 harbor]# docker push harbor.magedu.net/test/centos-base:7 The push refers to repository [harbor.magedu.net/test/centos-base] 076db42d2a09: Pushed 174f56854903: Pushed 7: digest: sha256:f24bb6fa09e33d9737a7e9385106f1e40624de4be2a111c027b579d9a9e8054a size: 742
push时提示证书错误
[root@ha1 harbor]# docker push harbor.magedu.net/test/centos-base:7 The push refers to repository [harbor.magedu.net/test/centos-base] Get "https://harbor.magedu.net/v2/": x509: certificate signed by unknown authority
X509v3 Subject Alternative Name: DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster, DNS:kubernetes.default.svc.cluster.local, IP Address:127.0.0.1, IP Address:172.20.0.112, IP Address:172.20.0.113, IP Address:172.20.0.114, IP Address:172.20.0.115, IP Address:10.254.0.1 ...
确认 Issuer 字段的内容和 ca-csr.json 一致;
确认 Subject 字段的内容和 kubernetes-csr.json 一致;
确认 X509v3 Subject Alternative Name 字段的内容和 kubernetes-csr.json 一致;
: {"level":"fatal","ts":1649936424.1166,"caller":"flags/flag.go:85","msg":"conflicting environment variable is shadowed by corresponding command-line flag (either unset environment variable or disable flag))","environment-variable":"ETCD_DATA_DIR","stacktrace":"go.etcd.io/etcd/pkg/v3/flags.verifyEnv\n\t/tmp/etcd-release-3.5.2/etc
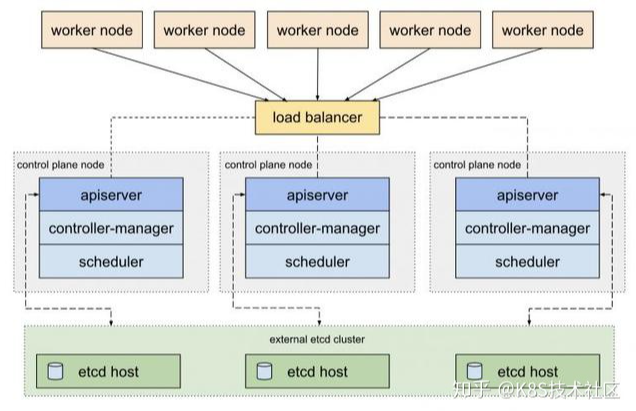
[root@master ~]# kubeadm init --apiserver-advertise-address=192.168.68.151 --service-cidr=10.1.0.0/16 --pod-network-cidr=10.244.0.0/16 # 151是mater本机的ip [init] Using Kubernetes version: v1.23.5 [preflight] Running pre-flight checks [WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly [WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service' [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master] and IPs [10.1.0.1 192.168.68.151] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost master] and IPs [192.168.68.151 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost master] and IPs [192.168.68.151 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for"kube-apiserver" [control-plane] Creating static Pod manifest for"kube-controller-manager" [control-plane] Creating static Pod manifest for"kube-scheduler" [etcd] Creating static Pod manifest forlocal etcd in"/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 6.003818 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config"in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.23"in namespace kube-system with the configuration for the kubelets in the cluster NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently. [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node master as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: v7a8ke.zqnhzofo3cn69lge [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+ podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created
## 此时只有一个node [root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane,master 132m v1.23.5
slave节点加入集群
[root@node-1 ~]# kubeadm join 192.168.68.151:6443 --token v7a8ke.zqnhzofo3cn69lge --discovery-token-ca-cert-hash sha256:6d362f1c226c8e8ae42a87f57608264104b58abd7ec5cfde4795353eba8c4a11 [preflight] Running pre-flight checks ^C [root@node-1 ~]# kubeadm join 192.168.68.151:6443 --token v7a8ke.zqnhzofo3cn69lge --discovery-token-ca-cert-hash sha256:6d362f1c226c8e8ae42a87f57608264104b58abd7ec5cfde4795353eba8c4a11 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
kubeadm 初始化报错18797 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""